
























Behaviors to rule them all!
In today’s world, machine learning and rule-based approaches are used widely across industry sectors for the purpose of making decisions based on the inference of data.
In today’s world, machine learning and rule-based approaches are used widely across industry sectors for the purpose of making decisions based on the inference of data. So, where do we use what? There are some applications that lend themselves well to machine learning whereas some are easy to do with rules. The purpose of the application(s) dictates the solution approach.
There are certain common aspects and key differences in the way that these systems work. Both need data to function. Relevant data is represented to the inference system which makes a prediction. These data elements are called variables in the case of rules and features in the case of machine learning models. Both approaches require a certain degree of subject matter expertise in order to build effective systems. That is where the similarity ends.
Rules are ‘deterministic’ in nature whereas machine learning is ‘probabilistic’ using statistical models. And yes, you can also do deterministic inference with statistical models. Machine learning understands and leverages trends, patterns, and behaviors in historical data and can predict an outcome based on the information it has learned from the features it is given.
The problem with rules
Input variability
Most of the variables that go into AML rules for banks are around amounts and counts. That might seem straightforward to process, but the reality is far from so. A bank typically has different types of customers. Consider a bank’s client list includes a school kid saving money from her piggy bank, a person who works a minimum wage , and a senior executive’s checking account. Their accounts are not going to look anything alike in terms of balances, transaction patterns, counts, and amounts.
Writing one rule for a situation is not going to work for all of them. In comes segmentation. What segmentation does is group the customers into different categories of customers who transact similarly. In our example, we come up with 3 segments – that makes 3 rules I need to maintain for one situation. Suppose the bank operates in 10 countries. Not all the customers in the 10 countries transact similarly. So, you multiply the rules times 10 for each country. You just ended up with 30 rules for one situation. Do you see where I am going with this? Rules-based systems ultimately get unwieldy, requiring constant tuning and massive machinery behind them to keep functioning.
The F-bomb
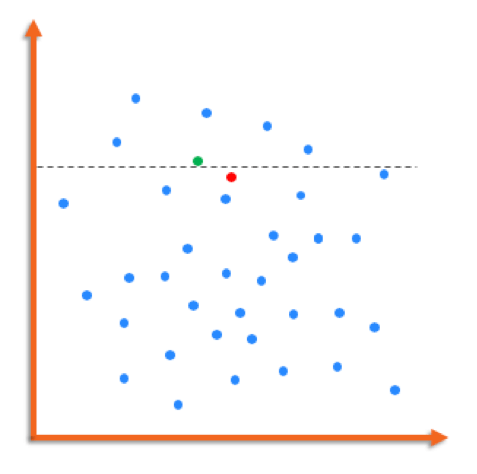
False Positives! The dreaded F word in AML. Think of a rule as a line that is splitting your population into two areas – one above the line and one below the line.
The AML risk represented at the bottom in the population above the line, represented by green, and someone who is at the top of the population below the line, represented by red, is not too different. But any given cut of the line will create trade-offs like this one.
The only way for a bank to capture the red dot with the green using rules, is to lower the rule threshold. Doing so allows the firm to capture the additional case but it also increases pick up of benign activity that are false positives. Reviewing these false positives drains valuable time, effort and money which could be spent on finding real suspicious activity.
Rules are static
Once rules have been defined and implemented, they do not have the ability to adapt to changing patterns and trends. ‘Tuning’ rules typically involve a large effort that goes back to the segmentation logic, review of all existing rules, defining new thresholds, testing these thresholds, adjusting and starting over. This is an unsustainable method in the long run.
Lucinity’s approach
You don’t need a deep learning algorithm to determine whether someone is from a high-risk jurisdiction or not. You are either doing business from a high-risk country… or you are not. For these cases, Lucinity quite simply uses rules to determine whether the behavior is taking place or not. However, when we move towards more complex behavior, rule-based approaches struggle.
Lucinity has devoted significant time to regulatory research led by our data science teams. The research results include a detailed list and description of every behavior the regulators deem to indicate possible money laundering. These are the behaviors that banks are regulated to report to the authorities who in turn decide whether criminal prosecution is warranted.
Lucinity decides what detection methods are applicable on a behavior-by-behavior basis. Lucinity will use a heterogeneous mix of techniques, dictated by the behaviors we need to cover for our clients. Some AML behaviors are better suited for basic statistical models while others are more sophisticated and call for deploying machine learning models like decision trees, neural networks, etc.
In any case, it is most important to us that we build a solid relationship with our partners and find the most efficient way to protect them from money launderers.
In the coming months, we will be diving deeper into some of these approaches. Stay tuned!

About Anush
Anush Vasudevan is the Head of Engineering and Data Science at Lucinity, the Intelligent AML company. Previously, Anush was the head of Citigroup’s AML solutions group for advanced analytics, where he was spearheading the effort to develop AML solution platforms through the use of machine learning. In a career spanning 10+ years with Citi, Anush has lead large-scale teams in building best-in-class solutions for varied business lines spanning consumer, institutional, cards, payment, and investment services. Prior to Citi, Anush worked with Oracle Financial Services specializing in product and services solutions to the banking and financial sector. Find Anush here.


